The World Now Has More Bot Traffic than Human Traffic
If half the internet isn’t a person, how much of what my expensive analytics stack is measuring is about people at all?

💌 Hey there, it’s Elizabeth from SigNoz!
This newsletter is an honest attempt to talk about all things, observability, OpenTelemetry, open-source, and the engineering in between.
This one took 4 days, 7 hours to cook, plus a slightly unsettling crawl through our own traffic logs.
Hope we served. 🌚
And if half the internet isn’t a person, then it’s most likely some rather non-human soul creeping on your diligently styled website from a server farm in Arizona. 😊

When my co-founder dropped a message in Slack saying the world now has more bot traffic than human traffic, my first reaction was, um, that sounds like bait, almost certainly missing an asterisk somewhere.
So I went looking for the asterisk, except that I didn’t really find one.
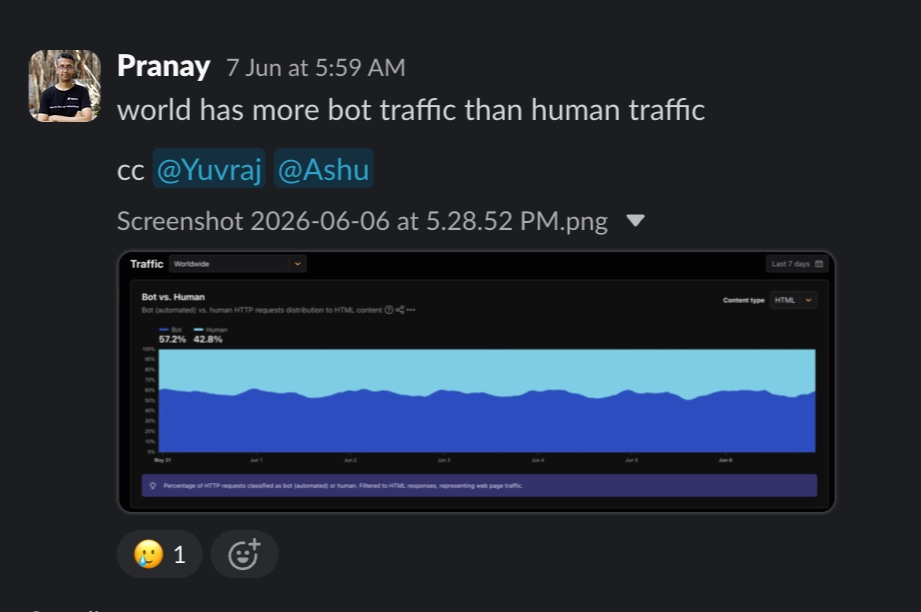
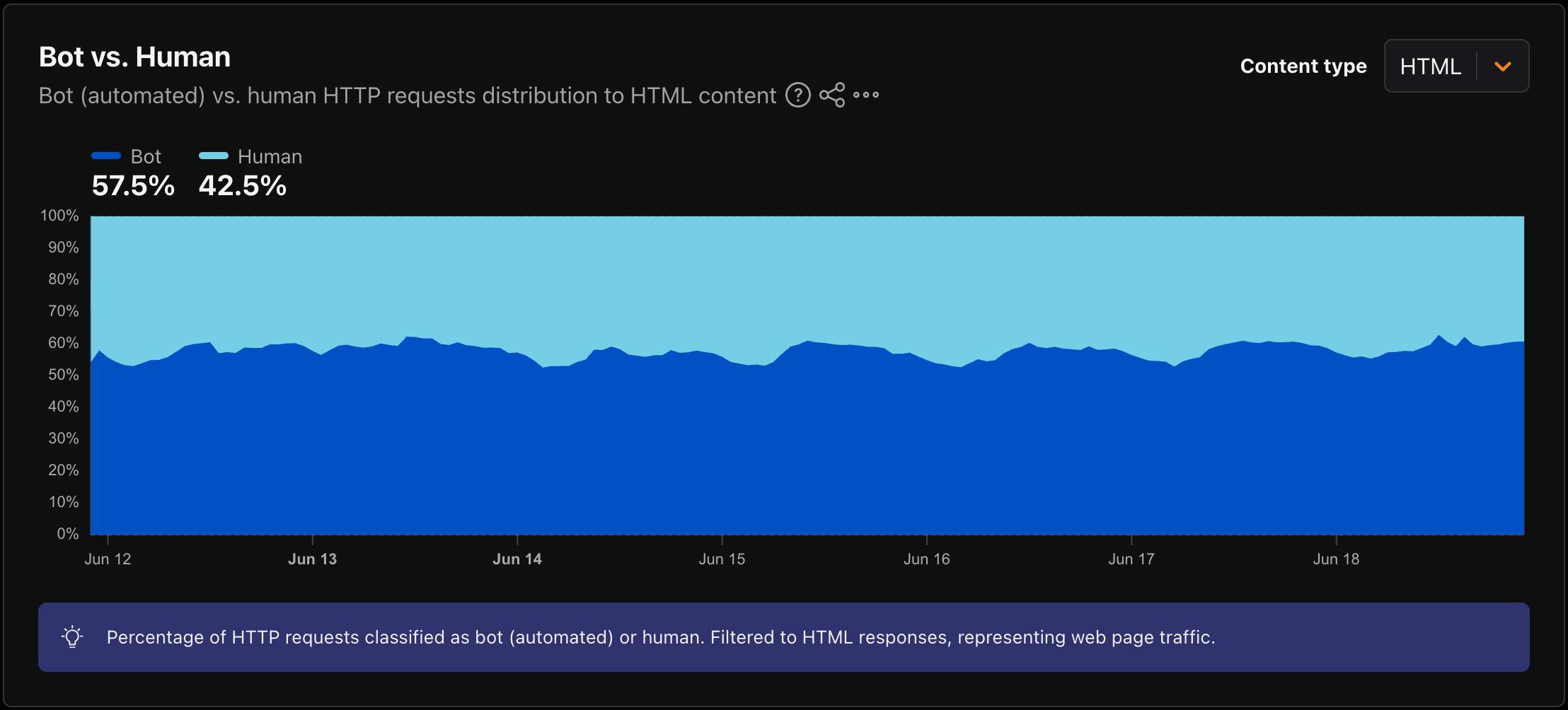
The 2026 Imperva Bad Bot Report puts automated traffic at 53% of all web traffic for 2025, up from 51% the year before. Cloudflare, looking at its own network in mid-2026, reported that for the first time in the internet’s history, more than half of HTML requests came from bots, roughly 57.5% versus 42.5% human. Cloudflare’s CEO had predicted that this crossover would happen around 2027, then pushed the date back because agentic traffic grew faster than almost anyone expected.
Which raises an uncomfortable question, if half the internet isn’t a person, how much of what my expensive analytics stack is measuring is about people at all?
Wait, hasn’t it always been like this?
This was my second instinct, that, maybe bots have quietly been the majority forever and we’re only noticing this now with the rise of analytics tools.
The sad answer is no.
When Imperva first started publishing this report in 2013, humans were about 57% of the traffic. Bot share actually fell through the mid-2010s, hitting a low around 2015 to 2018, largely because hundreds of millions of new human users came online across China and India, pushing the human share up. Bot traffic then climbed steadily from roughly 2018 onward and only crossed the 50% line in 2024. That’s why the reports don’t phrase it as the first time ever, but instead as the first time in a decade.
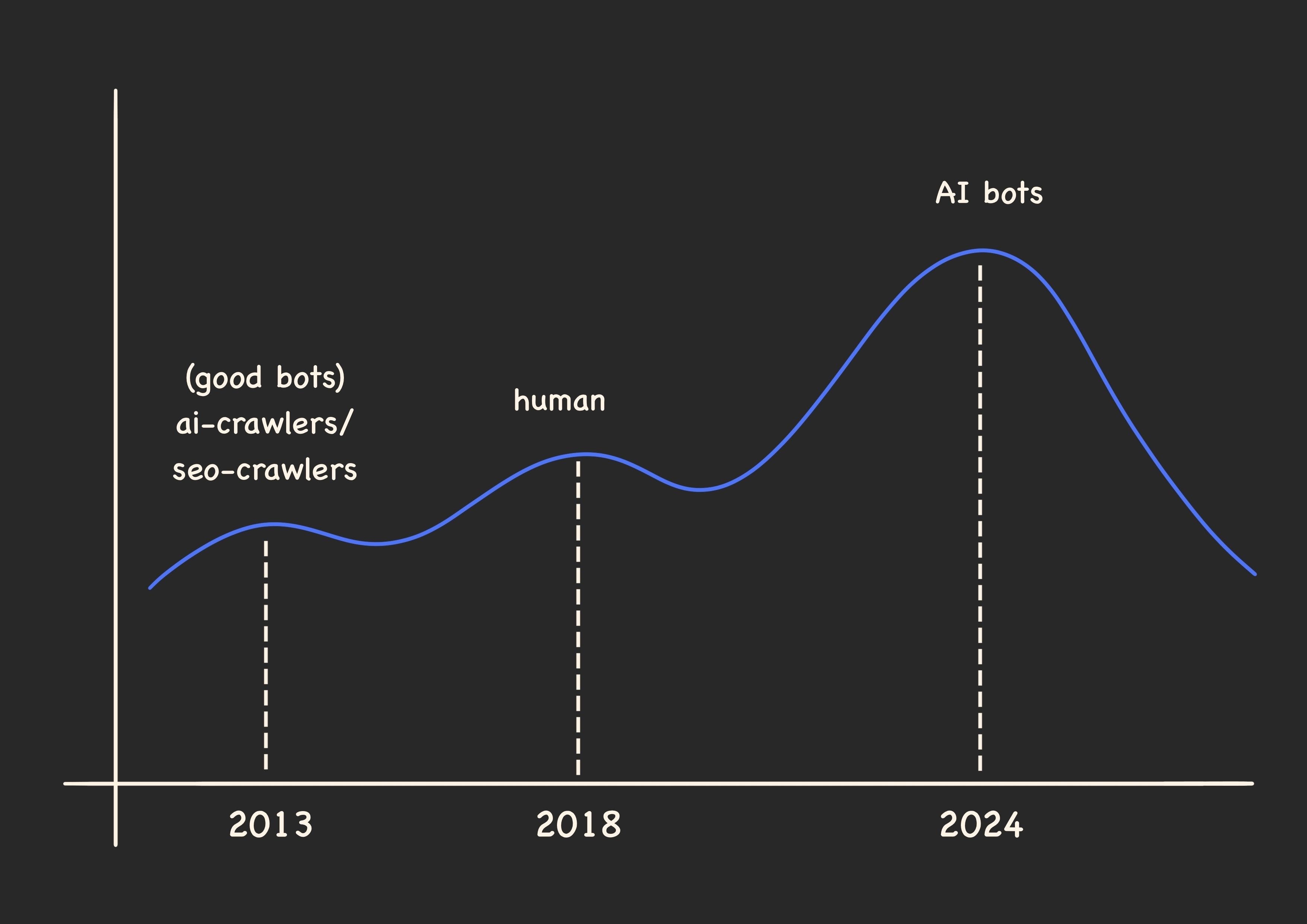
The exact figure is heavily methodology-dependent: Cloudflare has said the pre-generative-AI web was only about 20% bots, mostly Google’s crawler, while older reports measuring specific monitored sites showed bots as a majority years ago. So bots are more than half true under several current measures, but it wasn’t some eternal constant.
What’s robust is the recent inflection, and it’s very obviously AI-shaped.
How we actually see this at SigNoz
For our marketing website, we scrape the browser’s window object client-side, user-agent, IP, cookie and session state, whether the browser tab is even visible, and pipe all of it into Mixpanel. Then every page view gets sorted into one of two buckets.
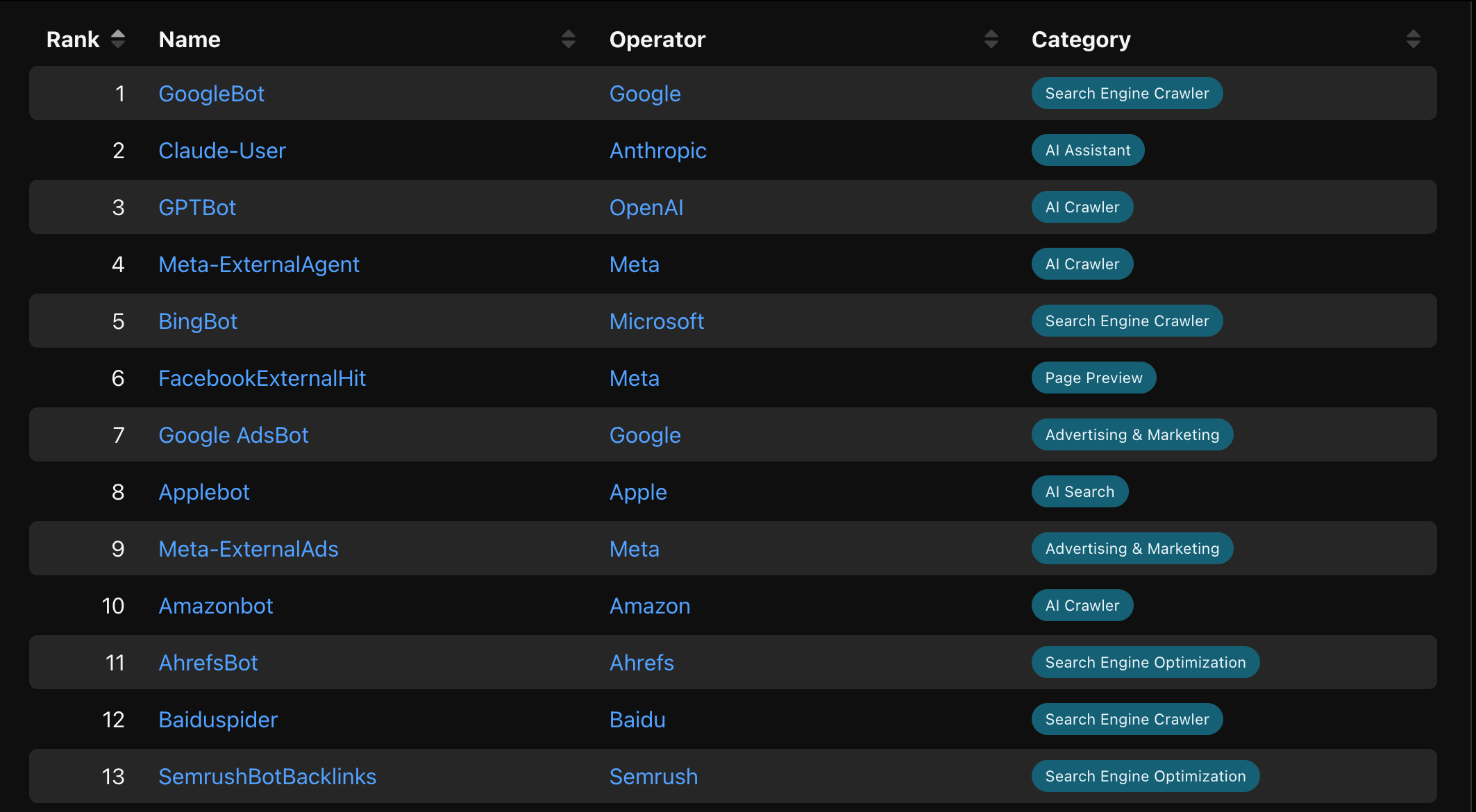
The first bucket is bot page requests, basically things we’re confident are bots. Most well-behaved bots announce themselves in their user-agent strings, such as GoogleBot, Bingbot, GPTBot, and friends. There are public directories of these, and we keep a dictionary in the repo and match against it. We also flag anything running headless, even if it didn’t identify itself.
Everything else falls into the second bucket, which is website page views, which are assumed to be human.
On inspection, somewhere around a quarter to a third of what lands in the human bucket are actually just bots we couldn’t identify at log time. A single user-agent firing thousands of hits inside a half-hour window, or my personal favourite, a bot that shows up at roughly 4 am every single day from a plain Linux x86_64 user-agent and quietly logs a couple hundred page views, like a very dedicated ghost.
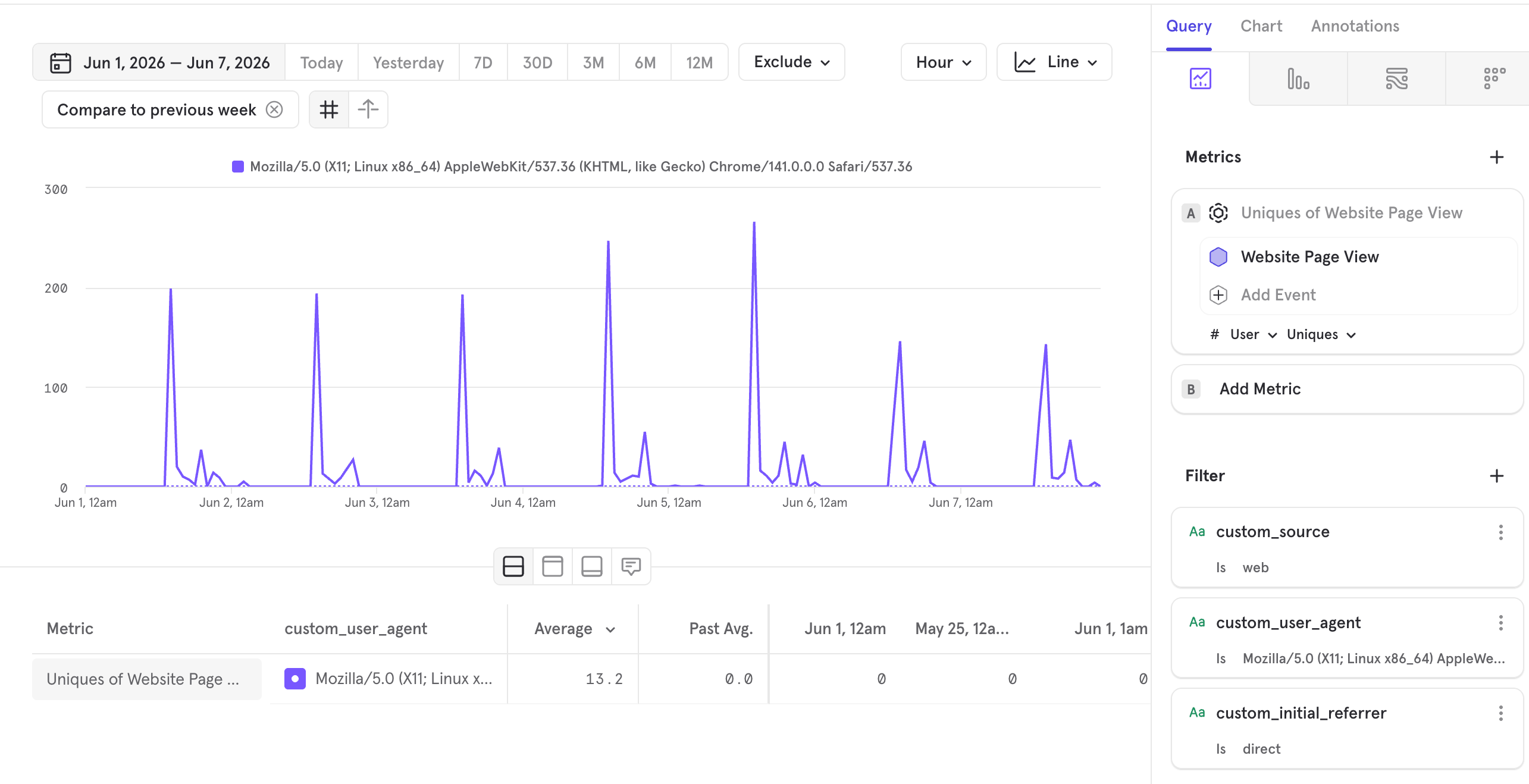
We clean these out retroactively, deleting thousands of phantom human events every week. Those bots, along with polluting the data, also require more storage for traffic that doesn’t even trace back to a human, and because Mixpanel bills per event, it could potentially hurt your pocket. (If you’ve ever stared at an observability or analytics bill and thought surely it isn’t all real, this is part of why it isn’t.)
Why is it all going up?
When I asked Yuvraj, our go-to person for all things ops and analytics on our team, why this is climbing, the answer came down to three things, and all three rhyme with the same word.
One, AI crawlers. The single biggest slice of our identified bot traffic is LLMs, say ChatGPT and Claude, fetching pages. Someone asks an assistant how to send data to SigNoz, and it comes and reads our docs in real time to answer.
Two, LLMs turned scraping into a one-liner that would previously have taken a scraping specialist hours. One of our team recently pulled the entire YC company directory, who’s hiring, what stack they use, the lot, end to end, because an LLM will just write the script for you on request.
Three, scraping-as-a-service.An entire product category now exists to crawl other people’s sites for you, including Firecrawl, Exa, Parallel, SERP APIs, Jina, and even Cloudflare, which now offers crawl endpoints that do the heavy lifting, primarily for marketing research purposes such as competitor tracking and staying on top of the game.
We notice that none of these are attacks with malicious intent but rather smart, legitimate automation, which makes it even harder to reason about.
The OpenTelemetry bit
Here’s the part I originally got excited about. OpenTelemetry almost has a ready-made solution for this. In the HTTP semantic conventions there’s an attribute called user_agent.synthetic.type, designed specifically to mark traffic as bot or test rather than genuine client traffic. It can be derived from user_agent.original, and the spec explicitly notes it’s useful for making sampling decisions.
In principle, that’s near perfect. You can classify the request, stamp the attribute on the span in the SDK or in the Collector, and then split every dashboard into human and bot segments and aggressively tail-sample the bot traffic.
It’s the same trick we do in Mixpanel, just standardized and portable across any backend. If you take one practical thing from this post, it should be to go set this attribute. 💁🏻♀️
But notice the load-bearing assumption in everything I just described, ours included. It all works only when the bot tells you it’s a bot, or is clumsy enough to ask for raw HTML, and that assumption is quietly falling apart today.
Let me tell you why.
The line between bot and human is dissolving
The fastest-growing kind of agent today is the one that nearly mimics a human. Think Claude in Chrome, ChatGPT’s Atlas browser or Perplexity’s Comet, the agentic browsers that became mainstream consumer products in barely a year. This is trickier because they don’t explicitly identify themselves as bots. They behave like real browsers but are controlled, watched and monitored by humans.
For example, I toggle the Claude in Chrome feature and ask it to fill out the sign-up form for SigNoz; it immediately spins up a browser and does it for you.
Basically, it shows up with a perfectly ordinary Chrome 149 user-agent plus cookies and a session that looks exactly like a person’s.
By early 2026, browser-based agents like Comet and Atlas accounted for roughly 70% of all agent traffic.
Some of them do leave a faint tell if you go looking. Atlas has been caught exposing a ‘ChatGPT Atlas’ string when it fetches a favicon, and a handful of agents are starting to ship dedicated user agents. But it’s inconsistent, easy to miss, and entirely up to the agent whether to be honest about it.
It isn’t lying to you, exactly. It’s a person’s intent, executed by a browser, acting on someone’s behalf. An agent acting for a human 🥷🏻
Does that count as a bot visit or a human visit? I’m not sure the question even has a clean answer anymore. 🤷🏻♀️
Yuvraj summed up the whole problem in a single offhand line, that he doesn’t really want to catch Codex, he just wishes Codex would put ‘Codex’ in its user-agent so he’d know. Until something like it is widely adopted, our analytics tools will quietly file agents under human, and the gap between what our dashboards report and what’s actually happening will keep widening.
The bigger picture
Is this a human?? is quietly becoming one of the most important dimensions in our data, yet almost nobody treats it as one. We average it away, and our percentiles, capacity plans, and conversion funnels are all blended across humans, honest bots, and an opaque, growing mass of agents in human costumes.
We talk about this in observability terms because that’s the world we live in at SigNoz. We build an open-source, OpenTelemetry-native observability platform, which means we sit on the raw traces, metrics, and logs rather than a pre-sampled summary of them. The thing this whole rabbit hole convinced me of is that human vs synthetic deserves to be a first-class dimension on that data.
So, has bot traffic always beaten human traffic? No. Is it winning now? Yep!
The score is almost beside the point, though. We’re losing the ability to tell the two teams apart, and we’re losing it on the dashboards we lean on every day to make decisions.