Why should a Trace-ID be 128 bits? (A Surprisingly Long Answer)
The answer touches probability theory, distributed systems constraints and fifteen years of industry migration. Let's actually dig in.

Every time I happen to use the trace tab in SigNoz (an observability platform), I’m met with the same question, and I put it in the “I’ll deal with this later” folder in my brain.
Until today, when I decided to address the 128-bit elephant in the room.
So, like a normal human these days, I searched on Google, “Why is a trace ID 128 bits long?”
And the answer was, surprisingly, a long one.

The answer touches probability theory, distributed systems constraints and fifteen years of industry migration. Let’s actually dig in.
What is a trace ID for, anyway?
When a request enters your system, say, a user clicks checkout, it might bounce through 20 different services, from your API gateway to auth to cart to inventory, etc. Each service does some work and may call other services. To reconstruct what happened when something goes wrong, you need a way to say “all these log entries and spans belong to the same original request.”
That’s the job of a trace ID. It’s generated once, at the entry point, and propagated through every downstream call via HTTP headers like traceparent(or other means of propagation).
So the trace ID has one job, uniquely identify one request’s journey through the system.
Back in our school days, to uniquely identify the students of a class, we had a system in-place which was incremental roll numbers. Why can’t we adopt something similar here, perhaps a counter system?
Why not just use a counter?
In short, counters need coordination. If Service A and Service B both want to generate trace IDs, they’d need to ask a central server to generate the next number and to remember the previously generated number.
To prevent this overhead, trace IDs are generated randomly, independently, with no coordination. Every service just picks a random number and trusts that it won’t collide with anyone else’s.
This is the entire reason the size matters: with no coordination, collision avoidance is purely a function of how large your random number is.
Now the dilemma is deciding how large this random number must be to effectively prevent collisions.
My first instinct was to think of just making the number big enough so that collisions are impossible. Let’s take 64 bits for now. 64 bits gives you 2⁶⁴; roughly 1.8 × 10¹⁹ possible values. That feels astronomical, and surely picking random numbers from a pool that large means collisions should be basically impossible.
The Birthday Paradox
This is where our intuition fails. Let me explain this with the birthday paradox.
Imagine a classroom of 23 students. What are the odds that two of them share a birthday? Instead of computing the probability that two people share a birthday, it’s easier to compute the probability that no two people share a birthday and then subtract it from 1.
P(no match)=365/365 × 364/365 × 363/365 × ⋯ × 343/365 ≈ 0.493So the probability that at least two students share a birthday is:
P(match)=1−0.493 ≈ 0.507Just over 50% with 23 people. This is the birthday paradox.

If we extend this paradox to trace-ids, we realise we are asking whether any two IDs in our entire trace history collide. Let’s understand this mathematically in the context of trace-ids.
The Math Behind The Paradox
This is a math-intensive section! If you want to understand every bit of this better, I suggest you lock in with a pen and paper. 🤓
Imagine you’ve generated 4 IDs: A, B, C, and D. A collision occurs when any two of them are equal. So let’s first list out all the possible pairs,
A & B
A & C
A & D
B & C
B & D
C & D
That’s 6 pairs. Each pair is one opportunity for a collision.
The formula for counting pairs is,
number of pairs = k(k−1)/ 2where k is the number of IDs. For large k, the difference between k and k-1 barely matters, so we can simplify as,
number of pairs ≈ k^2 / 2We observe that the key term (k^2) is quadratic, implying that if we generate 10× more IDs, you get 100× more pairs.
Counting expected collisions
Now we need to turn that pair count into something meaningful. Here’s the cleanest way to think about it:
Picture a dartboard with N spots on it. You throw k darts blindfolded and each dart lands on a random spot. A collision is when two darts hit the same spot.
The number of dart-pairs is k²/2
The chance that any single pair hits the same spot is 1/N
So the expected number of collisions is pairs × per-pair-chance = k²/2N
The Formula for Probability
Combining all those independent chances with a standard probability trick using the approximation 1 - x ≈ e^(-x) for small x, we land on the famous birthday-paradox formula, where k is the number of IDs, and N is the size (2^number of bits),
P(collision) ≈ 1−e^(-k²/2N)The important part of the formula is what’s inside the exponent: k²/2N.
Reading the formula in Plain English
The formula tells you a story in three acts, depending on how big k²/2N is. Here’s the graph for e^x, which makes understanding the acts easier.

Act 1: Safe.
When k²/2N is much less than 1, you’ve generated far fewer IDs, the exponent is near zero, e^(- near zero) ≈ 1, and collision probability is essentially zero. You’re fine.
Act 2: Danger.
When k²/2N is around 1, collision probability jumps to about 63%. You’re now more likely than not to have a collision somewhere in your set.
Act 3: Inevitable.
When k²/2N is much greater than 1, the exponent becomes huge, e^(-huge) ≈ 0, and collision probability rounds to 100%.
Now we have everything we need to answer the original question. Let’s circle back to it.
So why 128 bits?
The collision risk depends on the ratio k²/2N, and we can’t control k (the number of IDs generated).
What we can control is N (the size of the ID space), and N is determined by how many bits we use.
So the design question becomes: how big does N need to be so that even after years of operation, k²/2N stays comfortably in Act 1**?**
Let’s plug in 64 bits and see what happens. N = 2⁶⁴ ≈ 1.8 × 10¹⁹. Now let’s see how the collision probability evolves as k grows:
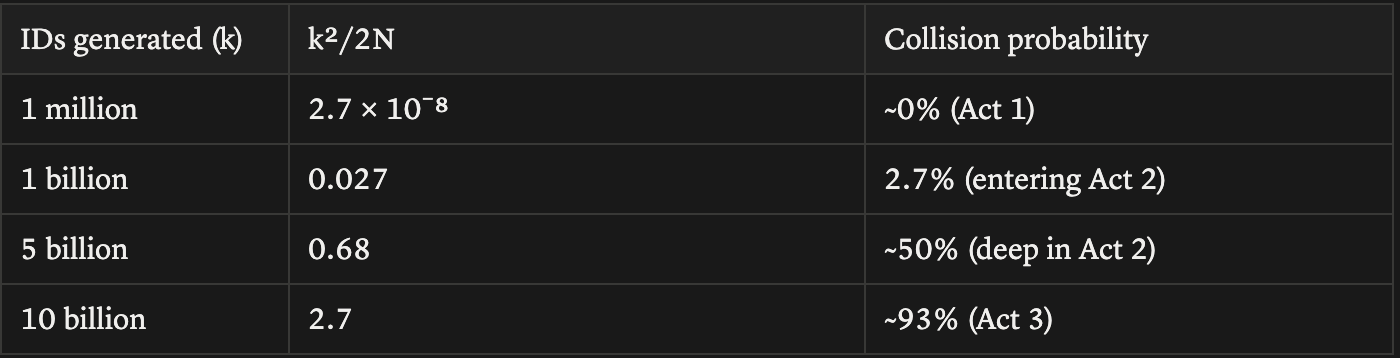
A billion IDs gets us to a 2.7% collision risk, and this will probably happen at any reasonably large company. And by 10 billion IDs, collisions are nearly guaranteed.
Now let’s redo the same exercise with 128 bits. N = 2¹²⁸ ≈ 3.4 × 10³⁸:
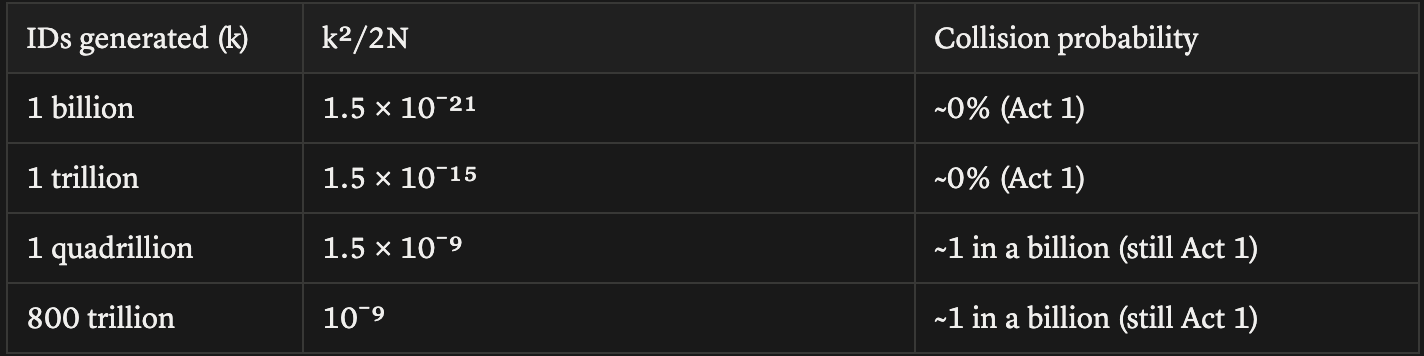
Even at a quadrillion IDs, k²/2N is still 0.0000000015. To reach a meaningful collision risk at 128 bits, you’d need to generate trace IDs in numbers that exceed every trace ever produced by every observability platform on Earth, combined.
We can’t stop k from growing, but we can choose an N so vast that the cliff in Act 3 sits beyond any horizon we’ll ever care about.
That’s why 128 bits.
Why not 256, then?
If 128 bits is good, isn’t 256 bits even better? Mathematically, yes. Practically, no.
Every trace ID has to be propagated on every HTTP request between services, stored alongside every span, indexed in every backend, and shipped through every log line. At scale, those bytes add up. 128 bits is 16 bytes; 256 bits is 32. Doubling the storage and bandwidth costs of every piece of trace data for a safety margin we already won’t reach in any realistic universe isn’t a trade anyone wants to make.
128 bits is the ideal sweet spot, collision safety effectively forever, and it happens to match the size of a UUID, which means every database, every language, and every protocol already knows how to handle it.
A tuff subject made human - congrats!