Our Project Hail Mary: The Observability Setup Behind an Observability Tool
Today, our internal observability system watches 6 regions, ingesting 21 billion metric points, 14 TB of logs, and 10 TB of traces. The story of how we got here starts with everything falling apart.

Hey there, it’s Elizabeth from SigNoz!
I wasn’t planning on making this a blog of its own and initially wanted to combine it with this. Later, when I got on a call with Pandey (the brains behind Nightswatch), I realised this deserved a blog of its own.
This is an attempt to do justice to the insane work our platform-pod does daily to keep all our customers’ cloud instances alive and stable. I hope you enjoy reading this as much as I enjoyed learning about this and crafting it for you.
Today, our internal observability system watches 6 regions, ingesting 21 billion metric points, 14 TB of logs, and 10 TB of traces per day without breaking a sweat.

We are people who build an observability tool for a living. We spend our days helping customers monitor their systems, debug their incidents, and make sense of their telemetry. So you’d think we’d have our own house in order.
We do now, but the story of how we got here starts with everything falling apart.
Our Early System
About 4 years ago, on an eerie Wednesday morning, one of our US cluster’s ClickHouse (our database) nodes started running hot, some queries were timing out, and a handful of customers were seeing slow dashboards. We followed the standard operating protocol of opening the internal monitoring tool, checking the metrics, and identifying the bottleneck.
Except the monitoring tool was down too.
SaaSMonitor, the system we’d built to watch our customer deployments, had been ingesting so much telemetry that its own collector had crashed.
This wasn’t a one-off event and kept happening.
Our internal monitoring grew organically over the years, starting with a hand-stitched setup called Testbed for our early manually provisioned customers, then SaaSMonitor was bolted on when we launched self-service sign-ups. This meant that if you were debugging something in the US region, you had to check two separate URLs.
Also, telemetry data went straight from collection to storage without a buffer in between, so any spike in volume would choke the pipeline. Every pod had two containers, an application and a sidecar, but metrics were only exposed at the pod level, implying that when something broke, you couldn’t tell which container was the culprit. There was no opt-in mechanism, and we collected everything from every pod by default, which meant we were drowning in data we didn’t need, making the volume problem even worse.
We tried some quick fixes, like putting an Envoy in front of SaaSMonitor as a load balancer, hoping that spreading traffic across more collector instances would prevent the crashes. It didn’t work because distributing an overwhelming load across more instances just gives you more instances that are overwhelmed. We needed something fundamentally different.
That’s when we started building Nightswatch, named after the Night’s Watch from Game of Thrones 🥷🏻. It was our Project Hail Mary, a single, unified system to observe every cluster, every node, and every container across SigNoz Cloud using SigNoz itself. It took our platform pod over a year, 21 issues, and a complete rethinking of how we observe ourselves.
This is the story of what we built.
This is also a masterclass on how we used almost all seven deployment patterns of the OpenTelemetry Collector. If you aren’t familiar with it, give this a read!
What are we observing?
Before we get into the story of how we built systems for observability, it helps to understand what exactly we’re trying to watch.
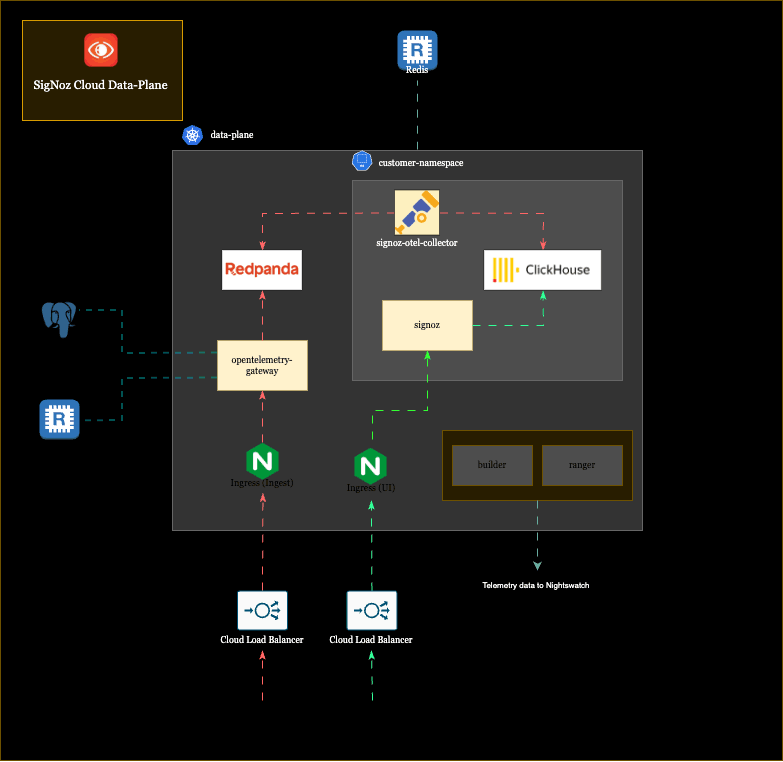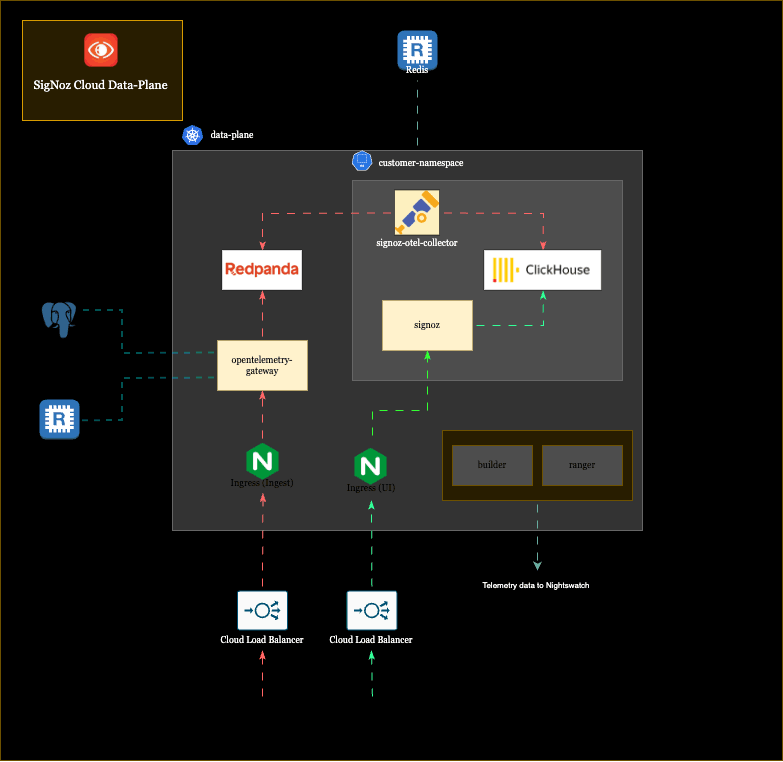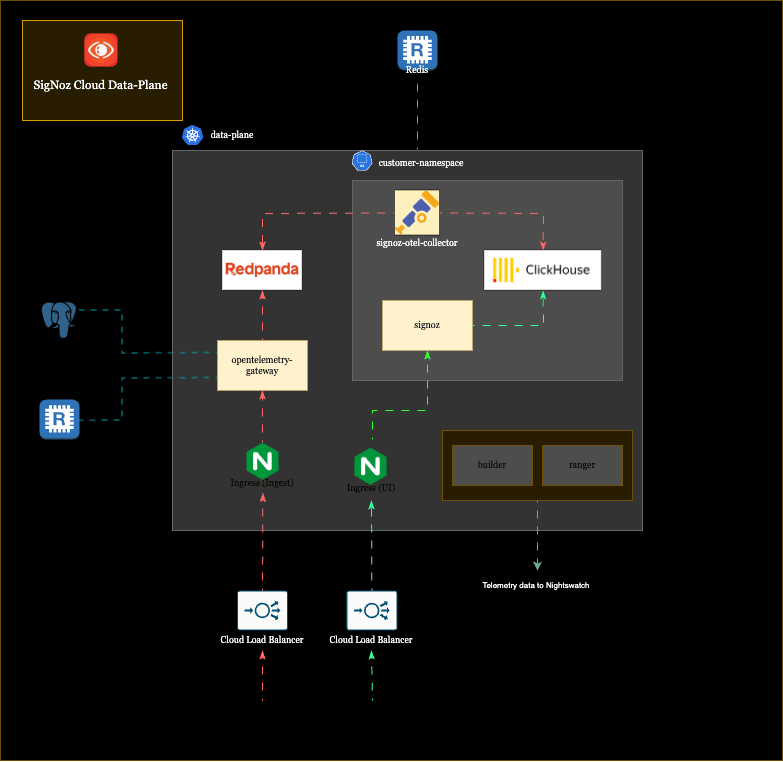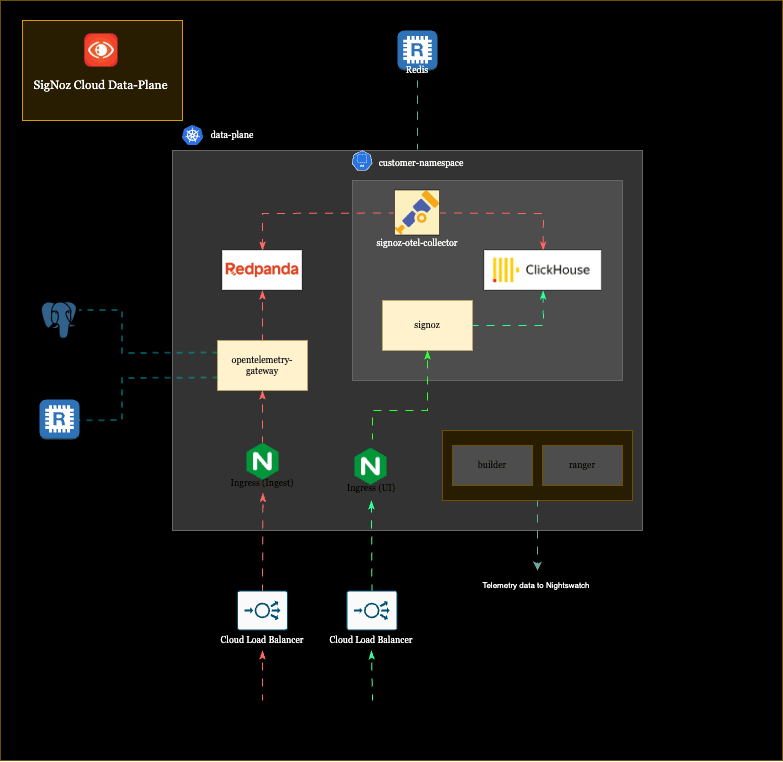
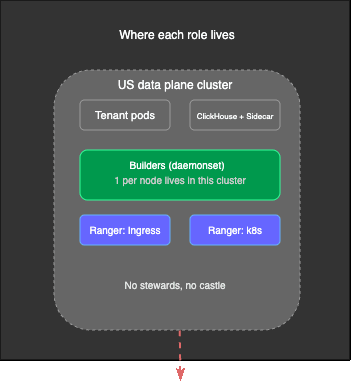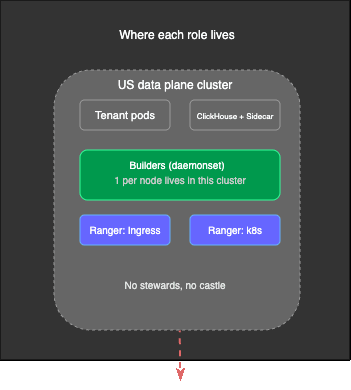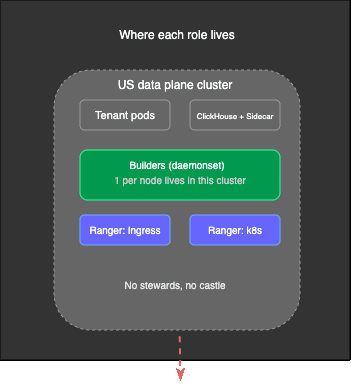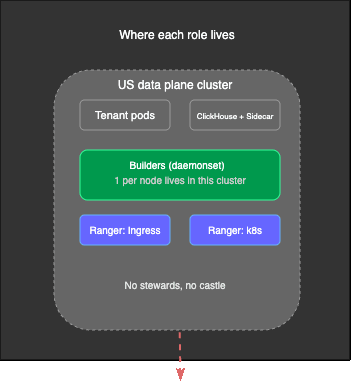
SigNoz Cloud is a multi-tenant platform, and we run three regional Kubernetes clusters across the US, EU, and India. When a customer signs up, they get their own isolated namespace within the cluster of their chosen region. Inside that namespace, they get their own SigNoz instance, their own ClickHouse for storing telemetry data, their own OTel collector for ingestion, and their own endpoint (something like acme.us.signoz.cloud).
Not everything is isolated, though; some infrastructure is shared across all tenants in a cluster. The Nginx controllers that route incoming traffic, the OpenTelemetry gateway that handles initial ingestion, and Redpanda (a Kafka-compatible streaming platform) that buffers data, are pooled resources that every tenant’s data flows through. But the core components where customer data actually resides and gets queried are fully siloed per tenant.
Here’s a slightly abstracted architecture of our customer’s data plane:
All of this, including the shared pipeline, the per-tenant components, both flows, across three regions and hundreds of customers, is what Nightswatch needs to observe. Monitoring all of this is what Nightswatch was built for, and, like its Game of Thrones namesake, it has a very interesting structure for guarding the realm.
Overview of Nightswatch
Nightswatch is our approach to running SigNoz to monitor SigNoz Cloud. Inspired by the Night’s Watch from Game of Thrones, the system is split into three roles, each named after a branch of the order.
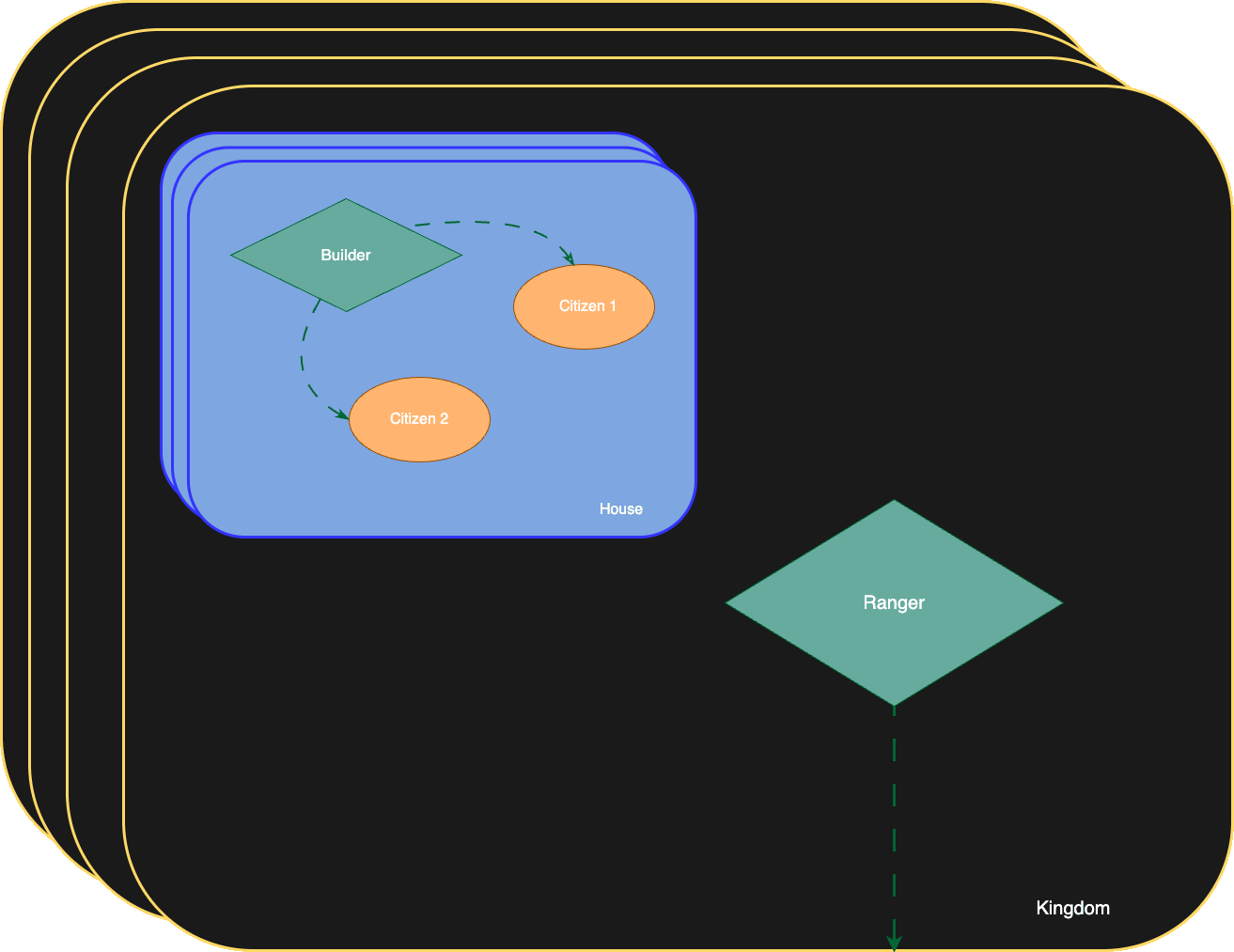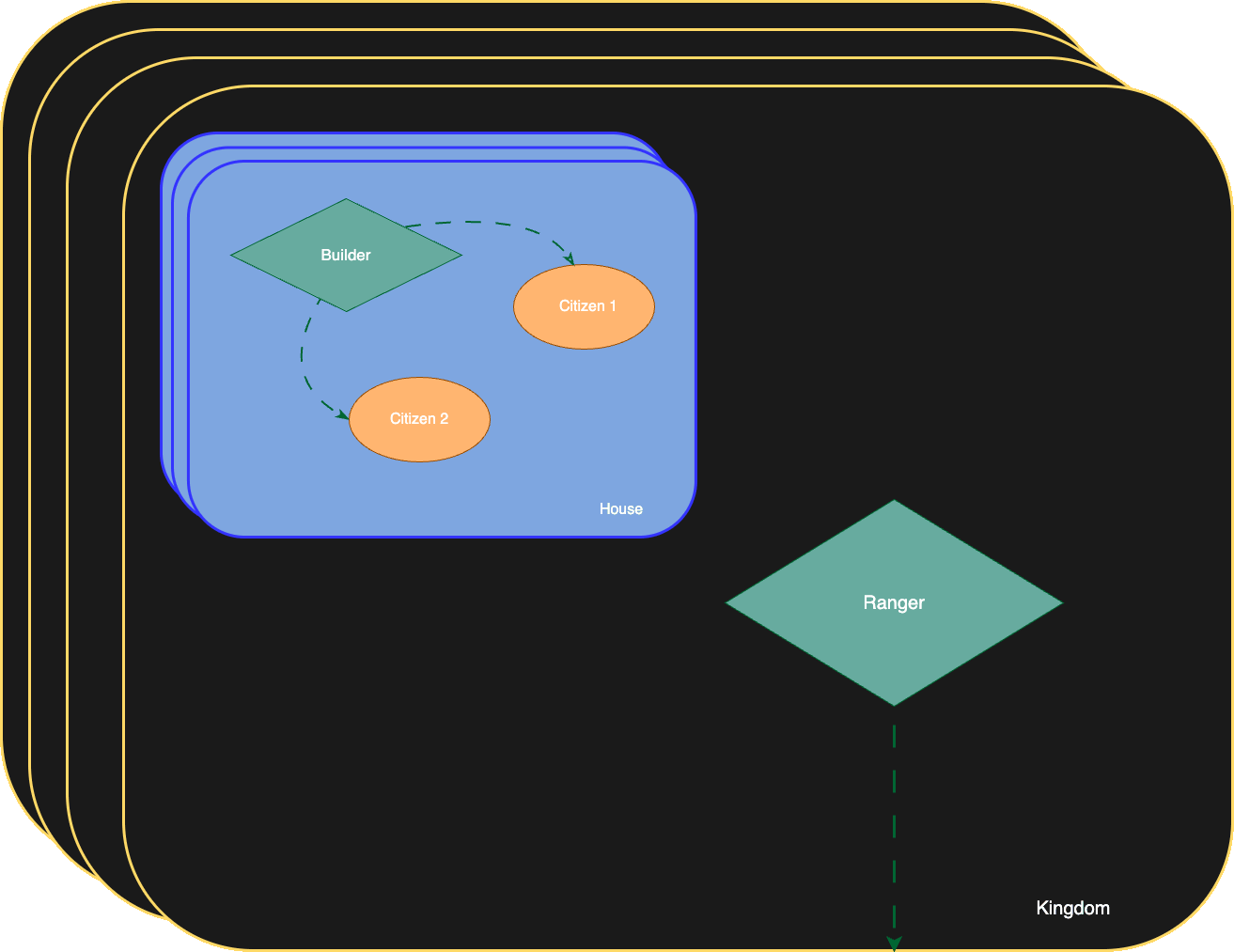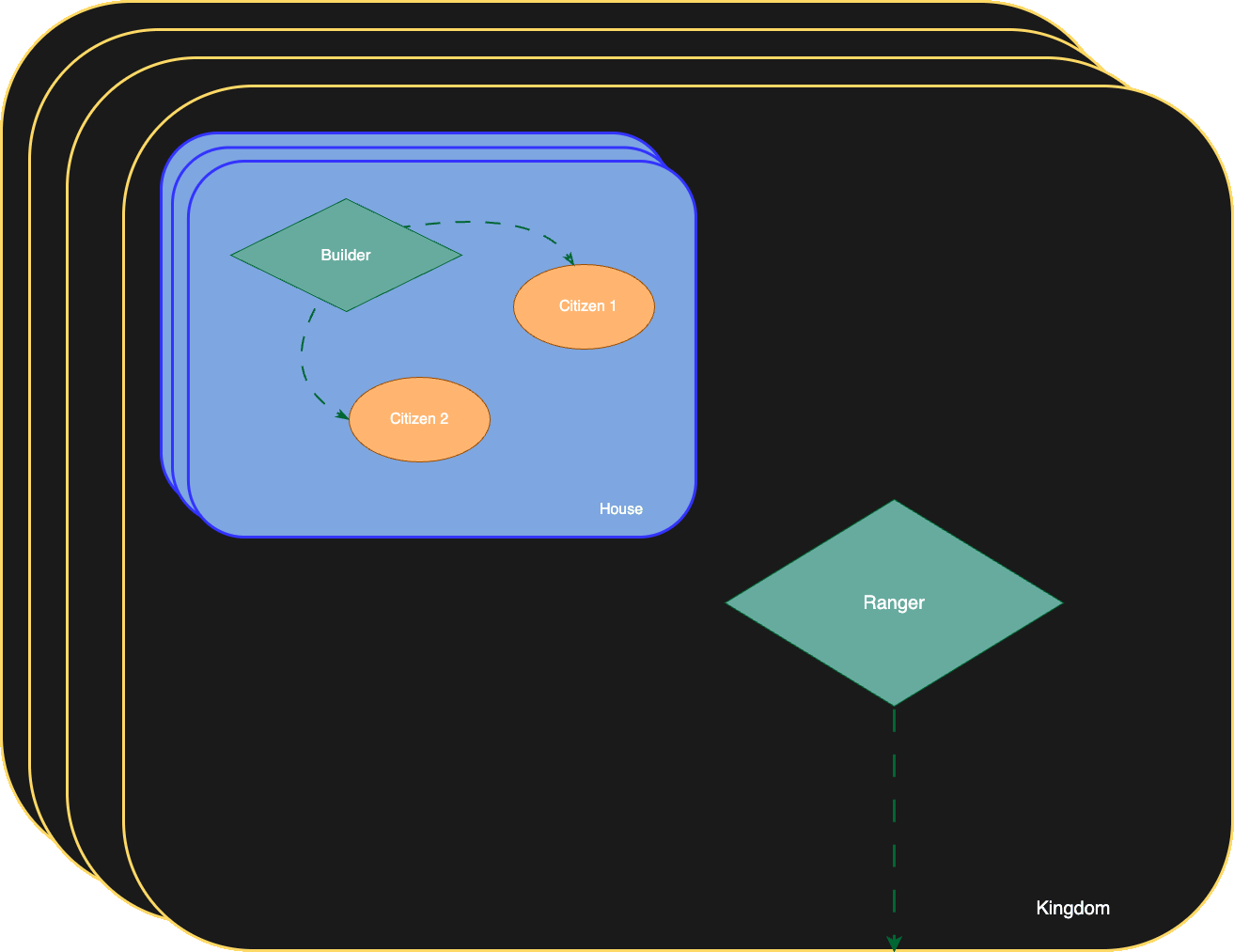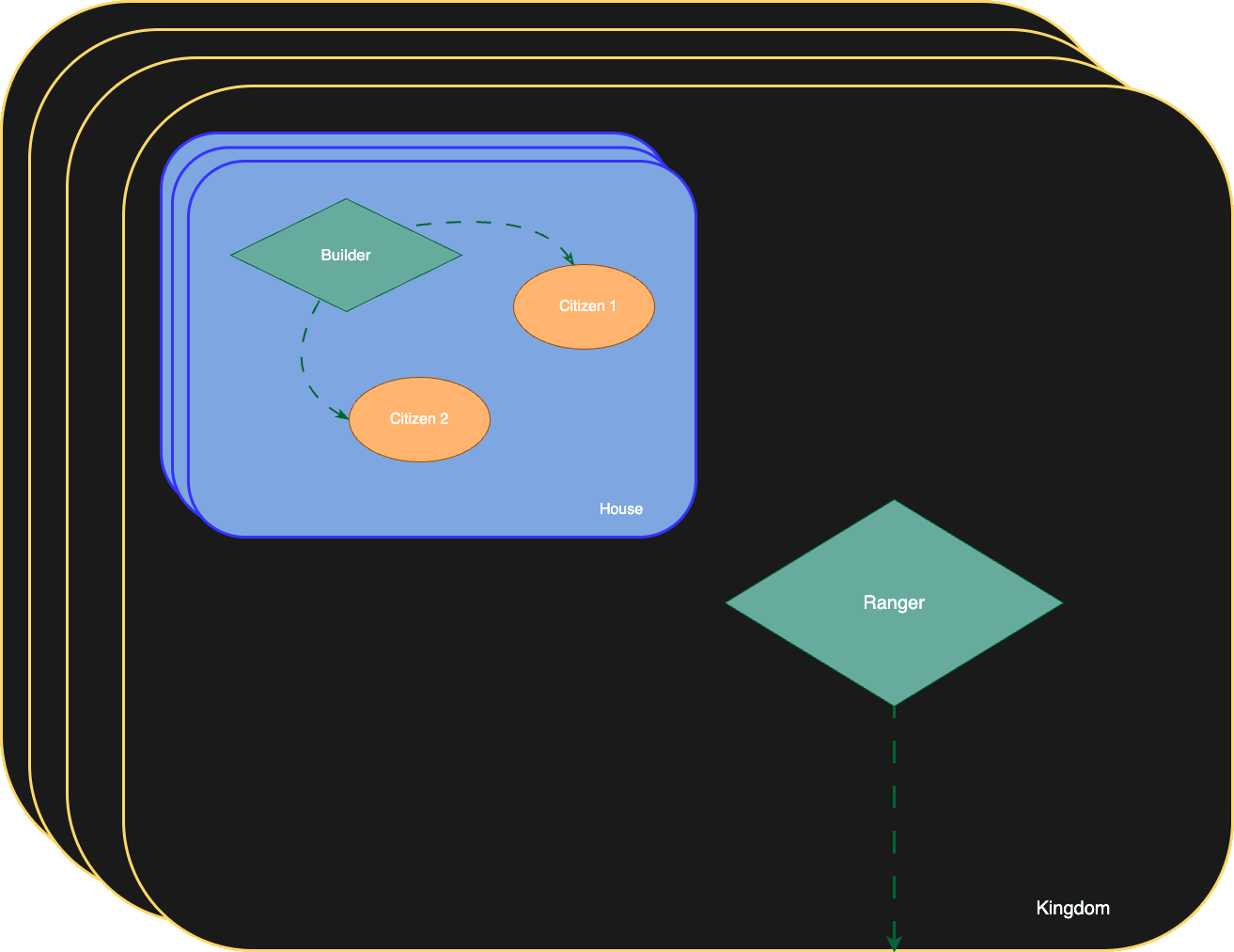
Builders man the Wall, and they run on every node, gathering metrics, logs, and traces from the pods around them. Rangers venture beyond it by actively probing customer endpoints and watching for cluster-level threats like node failures and pod evictions. Stewards keep the supply lines running, and they buffer and forward telemetry from builders and rangers to the Castle, a dedicated SigNoz instance where everything comes together.
Under the hood, all three are OpenTelemetry Collectors, each configured differently for its role, but the magic lies in how they work together.
Builders: Eyes on Every Node
I shall live to collect my house gossip and die at my post.
Builders are the most local members of the Watch, and each one cares only about what’s happening on its own node. They run as OpenTelemetry Collector daemonsets, meaning one builder per node in the cluster. If a node has 15 tenant pods, the builder on that node scrapes all 15. If another node has 3, that builder scrapes 3.
For metrics and logs, the builder uses a pull model, scraping each container’s /metrics endpoint (similar to how Prometheus works) and polling container log files on disk at a configurable interval. For traces, it flips to a push model: the application is instrumented with an OpenTelemetry SDK and sends traces directly to the builder’s OTLP endpoint.
Not everything gets collected by default, and this is an intentional change we brought in. In the old system, we collected everything from every pod with no way to opt out, which generated more data than we needed and contributed to the pipeline crashes. Nightswatch fixes this with a two-tier approach: node-level metrics like CPU, memory, disk, and network are always collected, because you never want a node on fire with no basic metrics for debugging, but container-specific metrics and logs are opt-in, controlled by annotations on the pod.
The annotation system is the heart of how builders work. In SigNoz Cloud, each tenant pod has multiple containers, such as the application and a sidecar OTel collector, each exposing metrics on different ports. Pod-level scraping can’t distinguish between them, which was another blind spot in the old setup.
Nightswatch annotations solve this by targeting a specific container within the pod, using <container> in the annotation name which gets replaced with the actual container name.
For metrics:
<OUR_DOMAIN>/<container>.mdscrape: true
<OUR_DOMAIN>/<container>.mdport: 8888
<OUR_DOMAIN>/<container>.mdpath: /metrics
n<OUR_DOMAIN>/<container>.mdinterval: 10s
For logs:
<OUR_DOMAIN>/<container>.ldscrape: true
<OUR_DOMAIN>/<container>.ldpipeline: json/nginx/...
<OUR_DOMAIN>/<container>.ldinterval: 200ms
The prefixes tell you the signal type:
md→ metrics discoveryld→ logs discovery
And each annotation controls a specific behaviour: whether to scrape, which port and path to hit, how often to scrape, and, for logs, which parsing pipeline to use.
Fun fact: This container-level scraping approach was something we built about 6-8 months before the OpenTelemetry community even started considering it.
Builders give you deep visibility into what’s happening inside every node, but they can’t tell you whether the customer’s endpoint is actually reachable from the outside, or whether the cluster itself is healthy. Here’s where rangers step in.
Rangers: Eyes on the Cluster
I shall live to probe and check the stability of my kingdom and die at my post.
Unlike builders, which run as daemonsets (one per node), rangers are deployments; we just need a replica running somewhere on the cluster. In our case, they run on a dedicated node pool reserved for Nightswatch workloads, so they never compete for resources with customer pods.
We run two types of rangers, each watching a different surface:
The ingress ranger acts as a synthetic customer. It periodically hits each customer’s endpoint, something like acme.us.signoz.cloud/healthz and checks whether it gets a healthy response. If it doesn’t, that could mean the customer’s SigNoz pod has crashed, or that the Nginx controller is misconfigured. Either way, the failure flows to the Castle as a data point and can trigger an alert immediately.
Like builders, the ingress ranger uses annotations to know what to probe:
<OUR_DOMAIN>/prdscrape: "true"
<OUR_DOMAIN>/prdpath: "/healthz"
<OUR_DOMAIN>/prdinterval: "10s"
The prd prefix stands for probe discovery, prdscrape enables probing, prdpath specifies which path to hit, and prdinterval controls how frequently it runs.
The k8s ranger watches the cluster’s infrastructure health by talking to the Kubernetes API server. It collects cluster-level metrics like node count, pod states, resource usage, and available capacity, giving us the big-picture view of whether a region is running healthy or approaching its limits.
It also captures Kubernetes events: whenever something notable happens, like a pod getting OOMKilled or a container crash-looping, the API server emits an event. The catch is that these events are ephemeral, meaning Kubernetes discards them after about an hour. The k8s ranger grabs them and ships them to the Castle as permanent records, which turns out to be invaluable for post-incident debugging.
Builders and rangers together give us full visibility of what’s happening inside each node, whether endpoints are reachable, and whether the cluster is healthy. But all that telemetry still needs to get somewhere safely. If the pipeline between collection and storage chokes, which is what kept killing the old system, none of this visibility matters.
This is why stewards are central pieces of Nightwatch.
Stewards: The Supply Line
I shall live to serve the builders and the rangers and die at my post.
Remember the core problem with the old system? Telemetry went straight from collection to storage with nothing in between, and any spike in volume would choke the pipeline. We actually tried fixing this once before, in V1, we put Envoy in front of SaaSMonitor as a load balancer, hoping that distributing traffic across more collector instances would stop the crashes. It didn’t work since distributing an overwhelming load across more instances just gives you more instances that are overwhelmed. A load balancer alone wasn’t the solution; we needed to engineer a complete buffer pipeline.
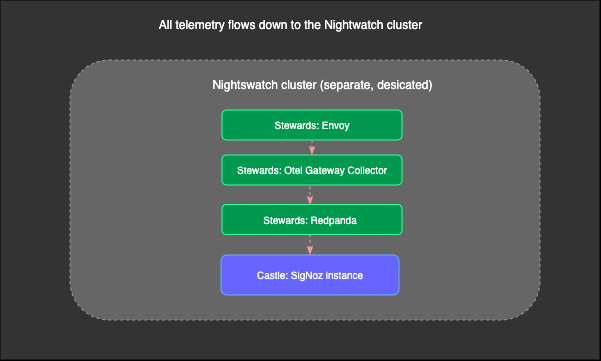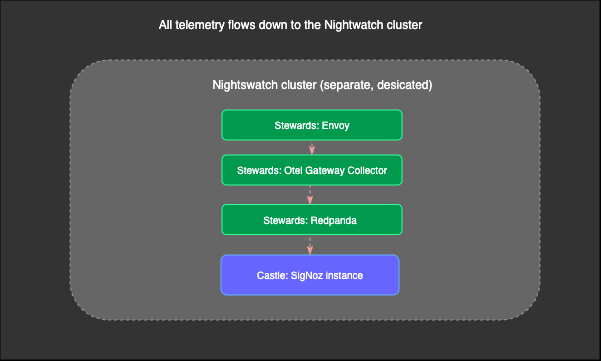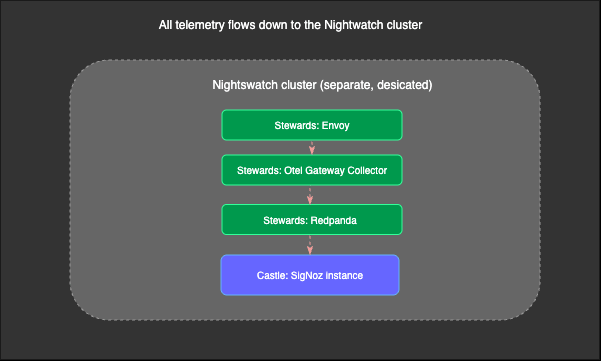
That’s what the stewards are: three OpenTelemetry Collectors working together to move data reliably from collection to storage.
Envoy sits at the front as the entry point. When builders and rangers from the US, EU, and IN clusters send telemetry, Envoy is the first thing that receives it, distributing incoming connections across however many OTel Gateway instances are running behind it. It’s gRPC-aware; the protocol OTel uses to ship telemetry, so it can distribute connections more intelligently than a basic TCP load balancer. The same component that failed in V1 works perfectly in V2, because this time it has the rest of the pipeline behind it.
OTel Gateway receives telemetry from Envoy, batches it, and forwards it downstream. It runs in gateway mode, meaning it doesn’t collect telemetry from local sources; it just receives, processes, and sends. The gateway is exposed via an internal load balancer without authentication, so builders and rangers in any region can send telemetry to the Nightswatch cluster without special credentials.
Redpanda is where it all comes together. It’s a Kafka-compatible streaming platform that acts as a durable buffer between the gateway and the Castle. The gateway writes data into Redpanda, and the Castle’s SigNoz instance consumes from it at whatever pace it can handle. If the Castle slows down or goes offline temporarily, data doesn’t get lost; instead, it queues up, and the Castle catches up later.
Castle
All telemetry ultimately flows into the Castle, which is a dedicated SigNoz instance. This lives in a separate management cluster (the control plane), completely isolated from the data plane clusters where customer workloads run.
This separation was deliberately implemented to prevent the castle from being affected if one of the region’s clusters crashed. The Castle also monitors itself by running its own builders and rangers.
Nightswatch was our platform-pod’s first-ever milestone spanning over 1 year and 3 months, 21 issues to build something we’re insanely proud of. And the Wall still stands. If building observability at this scale sounds like your kind of challenge, we’re hiring. Come join the Watch! 😉
Quite the evolution; strong stuff and impressive